
O Qlik Sense é uma das melhores ferramentas hoje no mercado para BI, sua engine de processamento consegue lidar com grandes volumes de dados e permite uma análise exploratória super ágil mesmo em milhões de registros, uma maravilha para um cientistas de dados. Como uma ferramenta de BI, seu foco não é geração de complexos modelos de machine learning, porém, nesse post, irei mostrar como criar, prever e analisar modelos por dentro da ferramenta, somando forças com o Big Query ML.
Esse é a Parte 1/2 sobre como implementar machine learning no Qlik Sense. No próximo post, vamos falar como criar previsões dinâmicas enquanto o usuário usa o aplicativo de BI.
Você vai ver nesse artigo:
- Formas de fazer Machine Learning com o Qlik Sense
- Criando a conexão com o Big Query
- Criando o modelo preditivo
- Gerando previsões com o modelo criado
- Avaliando a qualidade do modelo
- Como enviar dados do Qlik pro BQ
1. Formas de fazer Machine Learning com o Qlik Sense e Big Query
Atualmente existem 3 formas mais diretas de criar modelos por dentro do Qlik Sense, sendo uma nativa e duas com integrações.
Forma nativa (Regressão Linear e Clustering KMeans)
No Qlik Sense, você pode utilizar algumas funções para calcular modelos super simples, como uma regressão linear. Por exemplo, você pode utilizar o LINEST_M e LINEST_B para calcular o slope e o y-intercep de uma reta e usando a função LINEST_R2 para calcular o R².
Uma opção recentemente adicionada é o KMeansND, que permite uma clusterização simples dos dados.
Perceba que essas funções nativas são realmente simples e voltadas apenas para uma análise geral dos dados, não se tem o objetivo de criar modelos avançados para produção. Precisamos de outra solução…
Usando um Qlik Server-Side Extension (SSE)
É possível criar servidores que interagem com o Qlik Sense e permitem expandir o portfólio de funções disponíveis tanto no script quanto nos gráficos. Basicamente você sobe um server em Python, por exemplo, que recebe os dados do Qlik e retorna eles com algum processamento.
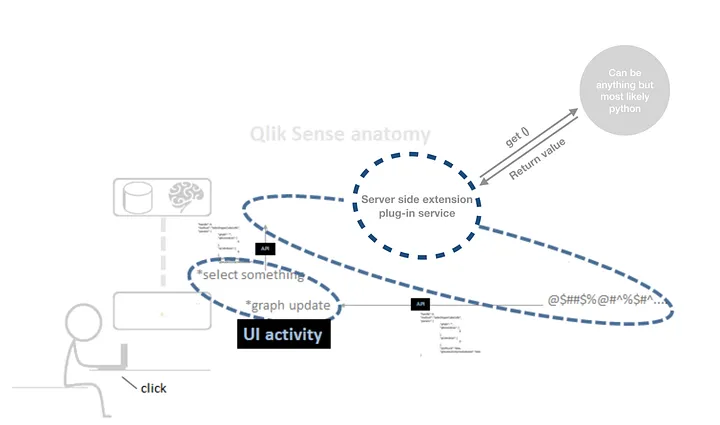
Um SSE famoso em Python é o qlik-py-tools, ele tem diversas funcionalidades que servem para script e gráficos. Com esse SSE é possível implementar modelos supervisionados, não supervisionados, deep learning, regras de associação, entre outras coisas. Sua grande vantagem é utilizar libs famosas em Python, como o scikit-learn, Keras e TensorFlow.
Qual a desvantagem então? Por que precisamos de outra forma?
O SSE não funciona no Qlik SaaS, tendo em vista o foco atual da Qlik na cloud, esse é um grande problema. Além disso, não é sempre que queremos mais um serviço para gerenciar, garantir sua performance e correção de bugs.
Usando Big Query ML
O BigQuery é um data warehouse totalmente gerenciado e sem servidor que permite análises escalonáveis em petabytes de dados.
Desenvolvido e gerenciado pela Google Cloud Plataform, o BQ hoje é uma das melhores soluções de bancos para Data Warehouse, sendo imensamente utilizado por grandes empresas como fonte analítica para os dados da organização.
E o Big Query ML?
Usando SQL simples, o BigQuery ML permite que cientistas e analistas de dados criem e operacionalizem modelos de machine learning (ML) em dados estruturados ou semiestruturados em escala global diretamente no BigQuery.
É uma ferramenta de alta performance e escala que permite criar modelos simples ou complexos, de forma manual ou com AutoML. A melhor parte, usando apenas SQL.
Por ser em SQL, abrindo uma conexão com o BQ no Qlik, podemos utilizar todas as suas integrações para criar e analisar modelos preditivos.
Exemplo de um código genérico de criação do modelo:
CREATE OR REPLACE MODEL model_name
OPTIONS(model_type=’linear_reg’, input_label_cols=['label_col'])
AS SELECT * FROM table
2. Criando conexão com o Big Query
Nesse demo, vamos utilizar uma base de cliente que possuem cartões de crédito. Nosso objetivo é tentar prever um possível churn desse cliente, ou seja, com base na movimentação de dinheiro feita, no tipo de cartão, no salário e na idade da pessoa, vamos prever qual a chance dela deixar de usar o cartão. Esse tipo de análise pode mostrar os clientes de maior risco e quais fatores são de maior impacto no churn.
A base de dados está disponível em: https://www.kaggle.com/sakshigoyal7/credit-card-customers
Os dados que iremos utilizar nesse projeto de exemplo já estão criados dentro de uma tabela no BQ.
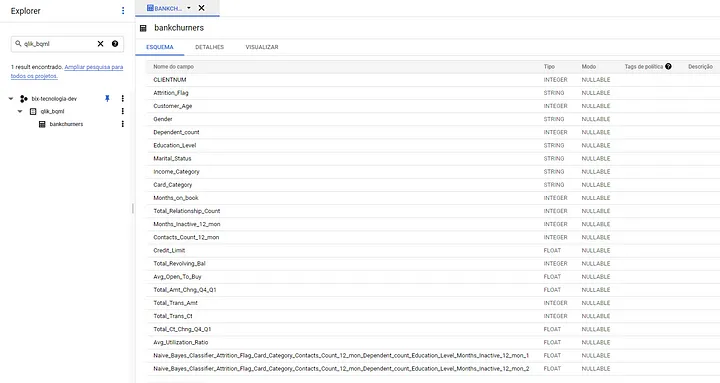
Nosso primeiro passo é tentar extraí-los no Qlik Sense criando uma nova conexão que aponta para o nosso dataset no BQ.
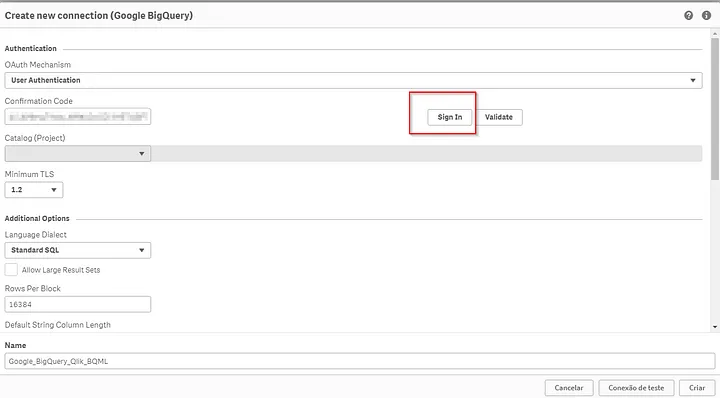
É muito importante nesse momento ativar a flag Allow non-SELECT queries. Vamos rodar alguns SQLs que não são um SELECT e não retornam dados, essa flag vai liberar que isso ocorra.
Com a conexão criada é só selecionar a tabela e gerar o código de extração. Com algumas alterações temos então:
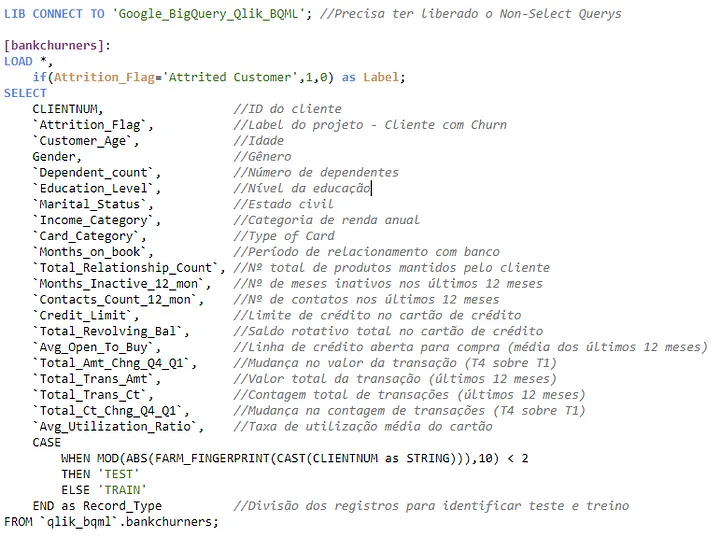
Pontos importantes nessa extração:
- O campo Record_Type foi criado para facilitar a separação dos dados que serão de treino e dos dados que serão de teste. O FARM_FINGERPRINT gera uma hash dos dados e permite separar a base de forma aleatória, porém reprodutível;
- Nossa label de previsão será o campo Attrition_Flag;
- Foi criado no Preceding LOAD o campo Label apenas para facilitar a visualização no Qlik;
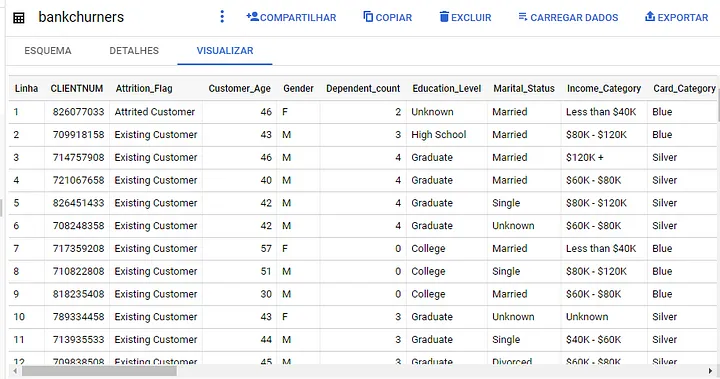
Assim já podemos começar nossa análise exploratória. Fiz uma tela básica com os dados para exemplificar:
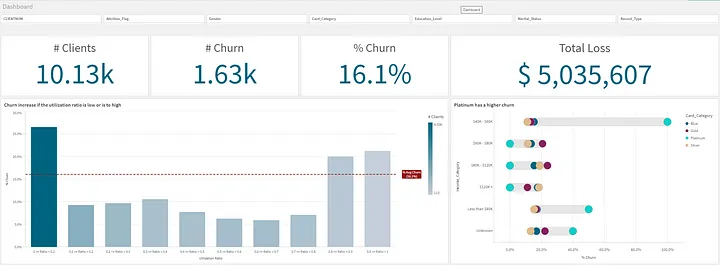
3. Criando o modelo preditivo
Para criarmos o nosso primeiro modelo é super simples. Utilizando a mesma conexão criada, vamos rodar o comando em SQL de criação do modelo passando a tabela com as features.
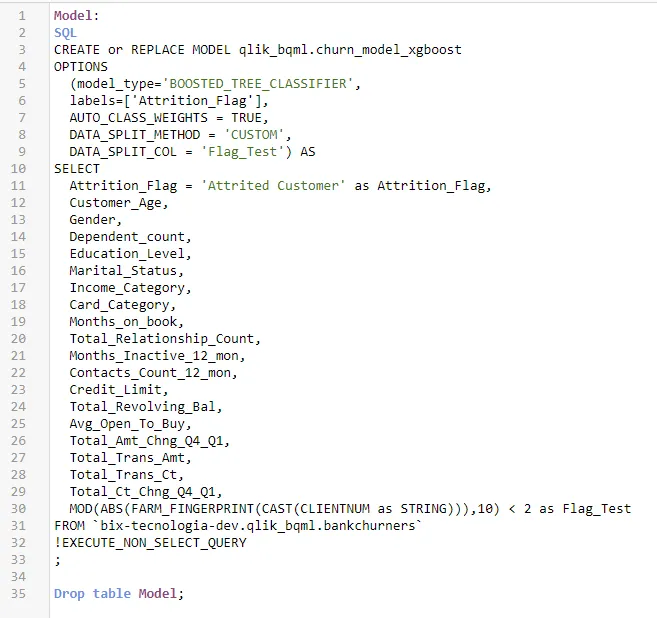
Pontos importantes:
- Na primeira linha definimos o nome do modelo e onde deve ficar armazenado;
- Criamos um modelo XGBoost para classificação, definindo um auto balanceamento entre as classes devido ao nosso problema de desbalanceamento;
- O campo Flag_Test foi utilizado para definir como deve ser feito o Split de teste e treino do modelo preditivo. Se não for passado nada, o split será aleatório;
- O comando !EXECUTE_NON_SELECT_QUERY é do Qlik. Ele é necessário quando o comando SQL não retornará nenhum dado;
- Nessa base, existem campos categóricos e números, repare como o BQML cuida de todo feature engineering pra gente;
A criação do modelo leva em torno de 8 minutos, porém uma vez feito, o código pode ser comentado.
Após a criação, você pode visualizar o modelo criado no workspace do Big Query, lá o Google já vai lhe mostrar dados de performance tanto para o treinamento quanto para o teste feito.
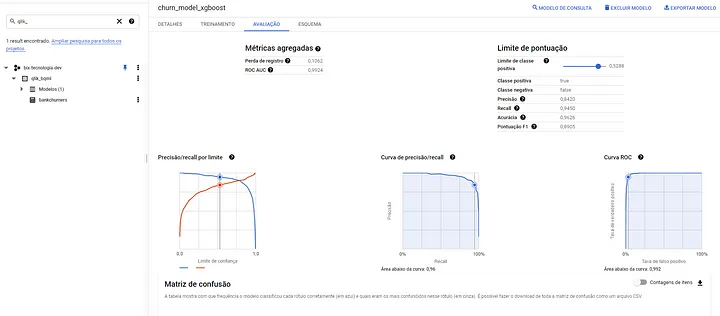
Vale comentar que há inúmeros outros modelos que o BQML tem suporte, tanto para regressão, classificação, forecasting, recomendação e AutoML. Alguns exemplos que podem ser utilizados no MODEL_TYPE são:
MODEL_TYPE = { 'LINEAR_REG' | 'LOGISTIC_REG' | 'KMEANS' |
'TENSORFLOW' | 'MATRIX_FACTORIZATION' |
'AUTOML_CLASSIFIER' | 'AUTOML_REGRESSOR' |
'BOOSTED_TREE_CLASSIFIER' | 'BOOSTED_TREE_REGRESSOR' |
'DNN_CLASSIFIER' | 'DNN_REGRESSOR' }
4. Gerando previsões com o modelo criado
Após o modelo ser criado, é possível enviar dados para ele e então gerar previsões. É como fazer um Select em uma tabela, porém agora a tabela é um modelo preditivo.
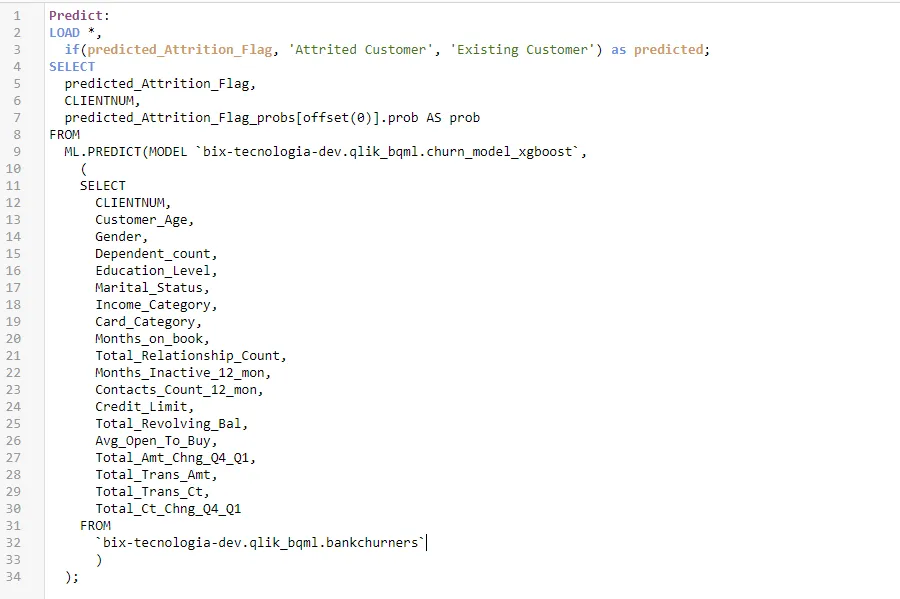
Pontos importantes:
- O campo CLIENTNU é uma chave única para o cliente, não sendo uma feature, entretanto, precisamos enviar junto para poder utilizar como chave para modelo associativo do Qlik;
- Nesta etapa, geramos as previsões tanto para os dados de treino quanto para os de teste. Podemos separar isso na visualização com o campo Record_Type previamente carregado.
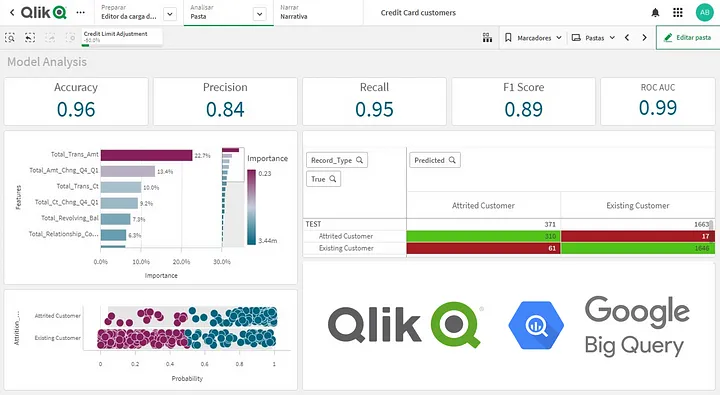
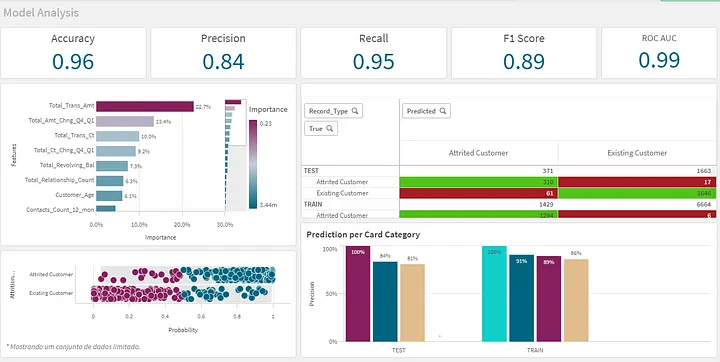
5. Avaliando a qualidade do modelo
Para avaliarmos a qualidade do modelo podemos simplesmente buscar as métricas já calculadas pelo google ou podemos trazer as previsões e fazer todo tipo de análise que o Qlik nos possibilita.
Duas integrações do BQML são úteis agora:
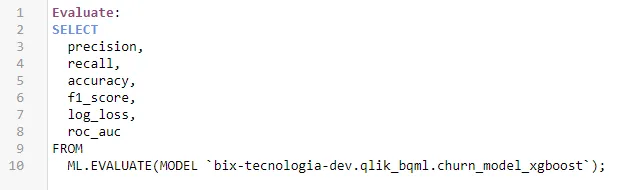

Com todas esses dados dentro da aplicação temos o seguinte modelo de dados:
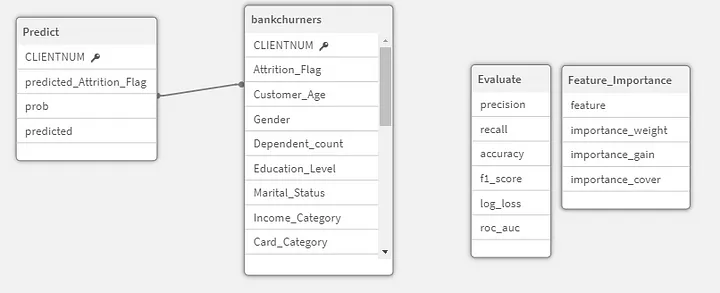
Utilizando o poder do Qlik, podemos fazer diversas análises complexas de performance do modelo, por exemplo, entendendo como ele se comporta para diferentes grupos de dados e não apenas no macro.
6. Como enviar dados do Qlik pro BQ
Uma das vantagens de utilizar o qlik-py-tools é que podemos fazer parte da ETL em Qlik Sense e então chamar o SSE via Script para gerar os modelos.
Nesse nosso exemplo enviamos o dado do próprio BQ para criar o modelo. É possível processar o dado no Qlik Sense e só depois enviar para o modelo?
No SaaS isso é possível, você pode salvar um CSV processado no Google Cloud Storage e então criar uma tabela no BQ que aponta para esse arquivo.
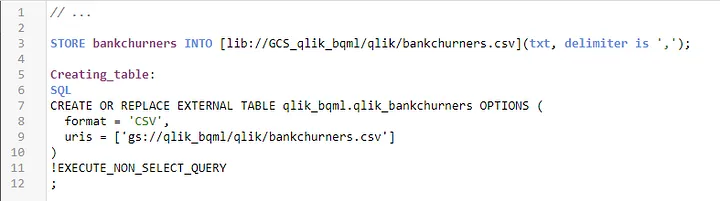
Com a tabela no BQ, basta agora utilizar como fonte das features na hora de criar ou prever com o modelo preditivo.
7. Próximo post, parte 2 — What If Analysis
A ideia do What if analysis é entender o que acontecerá com uma previsão se uma feature for alterada. Esse tipo de análise é incrível para um usuário de negócio que tenta identificar qual será o impacto de uma ação.
Para viabilizá-la é necessário um processo de previsão dinâmica, ou seja, o usuário vai definir uma alteração nas features enquanto usa o app e os objetos precisam ser atualizados com a nova previsão.
É possível fazer isso no Qlik Sense, porém, como exige falar de outros conceitos mais complexos, optamos por deixar na parte 2/2.
Conclusão sobre a relação entre Qlik Sense e Big Query
Utilizando a integração com o Big Query ML, temos acesso a uma imensa quantidade de funcionalidades na área de machine learning dentro do Qlik Sense e com ótima integração no SaaS. Além disso, o BQML garante uma implementação extremamente madura e gerenciada de forma segura como o Google Cloud Plataform.
Quer saber de qual a melhor plataforma para desenvolver o seu o projeto e trazer resultado para sua empresa? Entre em contato conosco! Vamos conversar sobre como analisar os dados do seu negóci da melhor maneira e com as melhores ferramentas!
Escrito por Angelo Baruffi